
Сегодня в СМИ
-
-
 Доля россиян, пользующихся подпиской на онлайн-кинотеатры, превысила 50%
Доля россиян, пользующихся подпиской на онлайн-кинотеатры, превысила 50% «Ъ» ознакомился с исследованием GfK о подписках на онлайн-кинотеатры. Из него следует, что доля россиян, пользующихся
-
 В мессенджер WhatsApp добавили генерацию изображений в реальном времени
В мессенджер WhatsApp добавили генерацию изображений в реальном времени Американская корпорация Meta (признана экстремистской и запрещена в РФ) добавила в мессенджер WhatsApp новую функцию,
-
 Хакеры атакуют популярный аналог западных соцсетей ЯRus
Хакеры атакуют популярный аналог западных соцсетей ЯRus Пользователи Сети начали активно регистрироваться в ЯRus после блокировки в России Facebook и ограничения вещания
-
 Зачем нужны SSL-сертификаты?
Зачем нужны SSL-сертификаты? SSL-сертификаты являются важной частью современного интернет-мира, так как они обеспечивают высокую безопасность и
-
 В Android 15 появится функция оценки состояния аккумуляторов смартфонов
В Android 15 появится функция оценки состояния аккумуляторов смартфонов В Android 15 появится новая функция, которая будет оценивать состояние аккумуляторов смартфонов. Речь идет и о
-
-
- AdSense AdWords Android AOL Apple Bing Facebook google Google AdWords Instagram Mail.ru Mail.ru Group Microsoft rambler telegram Twitter Vkontakte WhatsApp Yahoo YouTube Контекстная реклама Мэтт Каттс Однокласники Раскрутка Реклама Россия Яндекс.Директ Яндекс Директ бегун в контакте интернет новая функция новости обновление однокласники поиск пользователи продвижение рунет сайт социальная сеть социальные сети статистика тестирование яндекс

На чем я зарабатываю:

Где раскручивать сайт:

Архив записей
-
Новости о Google
1 ноября 2008 года | Поисковые системы
-
Google подготовил третью бета-версию своего браузера

Компания Google разработала третью бета-версию браузера Chrome, сообщает Computerworld. Дату выхода новой версии Chrome разработчики не уточнили, но подчеркнули, что она появится в ближайшее время.
Третья бета-версия Chrome с порядковым номером 0.3.154.9 исправит ранее обнаруженные в браузере ошибки. Также была улучшена система безопасности браузера. Например, в Chrome 0.3.154.9 усовершенствована система блокировки всплывающих окон.
Также в новой версии Chrome улучшена работа с Flash, QuickTime и Silverlight. Кроме того, в Chrome 0.3.154.9 обновили систему проверки орфографии и заблокировали функцию автоматического скачивания и запуска исполняемых файлов.
Бета-версия браузера Google Chrome была выпущена второго сентября текущего года. Неделю спустя Google представил новую версию Chrome, в которой были устранены найденные уязвимости. По данным компании Net Applications, за месяц Google Chrome занял один процент рынка браузеров.
Онлайн-энциклопедия Google стала многоязычной
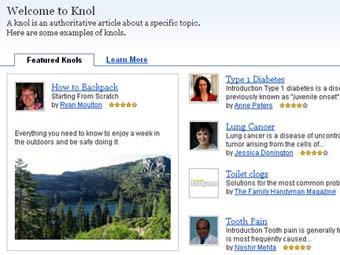
Компания Google объявила о том, что онлайновая энциклопедия Knol стала многоязычной, сообщает агентство France Presse. В настоящее время Knol, помимо английского, доступна на французском, немецком и итальянском языках.
Сервис Google Knol был запущен в конце июля текущего года. Его бета-тестирование началось в конце 2007 года.
В отличие от онлайновой энциклопедии Wikipedia, каждый материал в Knol подписан автором, либо группой авторов. Кроме того, в Knol допускается присутствие нескольких статей на одну и ту же тему, отображающих различные точки зрения.
Автор статьи в Knol может сделать свой материал открытым для редактирования, как в Wikipedia, либо закрытым. В последнем случае читатели смогут отправить отзыв автору материала со своими предложения по редактированию текста. Также читатели могут оставлять комментарии к текстам Knol.
Поисковик Google научился различать слова на изображениях
Компания Google разработала систему оптического распознавания текста. Она позволяет поисковику различать текст на отсканированных изображениях. Об этом сообщается в официальном блоге Google.
В настоящее время Google способен распознать текст на изображениях, сохраненных в формате PDF. О планах Google по расширению возможностей системы не сообщается.
Поисковик уже начал индексировать PDF-файлы. Наибольшую сложность представляет поиск по старым отсканированным документам, где бумага, например, испачкана следами от чашки с кофе, либо имеются различные пометки, сделанные от руки.
Ранее Google запустил в экспериментальном режиме сервис Google Audio Indexing, распознающий звуковую дорожку в видеоклипах. Он конвертирует звук в текст и индексирует последний.
Кроме того, в начале сентября Google сообщил о планах по размещению в интернете отсканированных страниц старых газет и журналов. Они будут помещены в новостной архив поисковика и появятся в результатах поисковой выдачи.
Последние комментарии
mogzem: Полезная информация для родителей - на что обратит »
Вадим: Спасибо за новость »
Анастасия: Очень люблю такую маску! Кстати, мёд тоже :) Ещё я »
onlinemixx: А спецы америкосов стопроцентов уже давно имеют до »